
China Is Reverse-Engineering America’s Best AI Models
How AI distillation attacks risk extracting US frontier AI at scale



This post was co-authored by Peter Wildeford and Theo Bearman, a Frontier Security Researcher at the Institute for AI Policy and Strategy (IAPS). It reflects their personal views only, not necessarily the position of their organizations.
~
Last month, Anthropic, OpenAI and Google each published evidence of systematic campaigns by Chinese AI companies to extract capabilities from American frontier models at industrial scale. Anthropic attributed attacks to three Chinese AI companies — DeepSeek, Moonshot, and MiniMax.
Anthropic’s investigation identified over 16 million exchanges generated through approximately 24,000 fraudulent accounts, all targeting Claude’s agentic reasoning, tool use, and coding capabilities. Chinese AI developer MiniMax was solely responsible for over 13 million of those exchanges. OpenAI also reported that Chinese actors had systematically targeted their ChatGPT models with distillation attacks designed to recreate the whole AI model training pipeline. And this is not the first time — in January 2025, White House AI czar David Sacks told Fox News there was “substantial evidence” that DeepSeek had built their model from distilled knowledge from OpenAI’s models.
Left unaddressed, AI distillation attacks pose a threat to American national security and economic competitiveness, given that they lead to China or other adversaries being able to develop better AI than would otherwise be possible by what is essentially stealing American technology. But what is a distillation attack and what can we do about it?
What is a distillation attack?
An AI distillation attack occurs when a malicious actor uses the outputs of a “teacher” model to train a “student” model to approximate the teacher’s capabilities. Think of it like a restaurant owner who reverse engineers the recipe of a nearby Michelin starred restaurant’s prized dish by going there hundreds of times, ordering it each time, and figuring out their list of ingredients, measurements, and cooking instructions. In the AI context, the “recipe” is the billions of dollars of research, compute, and training data that goes into building a frontier model. The “dish” is the model’s outputs — the answers it gives and the intermediate reasoning steps it took to get there. By collecting enough outputs, an attacker can train a new model that mimics the original’s capabilities without doing as much underlying research and development work.
To be clear, distillation also has legitimate applications in the AI industry. It can be used to create efficient models suitable for edge deployment, specialize general-purpose models for specific domains, and reduce inference costs. Major AI providers including Google Cloud and OpenAI offer official distillation pathways for their customers. The difference is intent. Distillation attacks aim to replicate frontier capabilities in a rival model, violating terms of service and skipping the R&D investment required to build those capabilities independently.
Additionally, the actual magnitude of capability transfer from distillation is unclear and disputed. Integrating another model’s outputs into your own training pipeline is a genuine research challenge — the data can interact unpredictably with existing training, and the resulting model doesn’t always improve. Reasonable people disagree on assessing the magnitude of the threat as it depends on how effectively attackers can solve this problem, which is not yet clear.
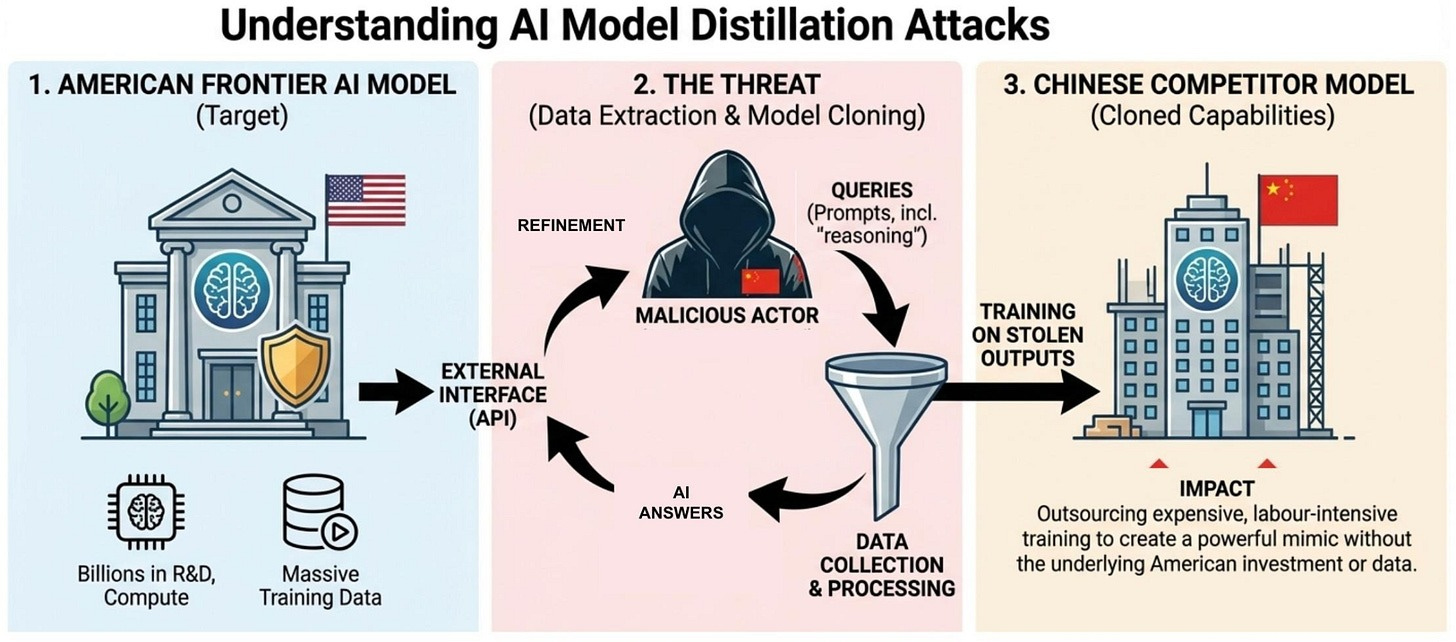
How the attacks work
Accessing American frontier AI models in the first place can require circumventing geographic restrictions. Anthropic, for example, does not offer commercial access to Claude in China. To get around this, Chinese AI companies use commercial proxy services that resell access at scale. These proxies operate what Anthropic calls “hydra cluster” architectures — sprawling networks of thousands of fraudulent accounts that distribute traffic across the target company’s API as well as third-party cloud platforms. In one case, a single proxy network managed more than 20,000 accounts simultaneously, mixing distillation traffic with unrelated legitimate requests to avoid detection. When one account is banned, a new one takes its place.
This is a structural problem that no single AI company can solve alone. Proxy services profit from facilitating unauthorized access to frontier models – as they are paid per access, they are incentivized to facilitate as much distillation as possible. Individual AI companies can play whack-a-mole with fraudulent accounts, but the proxy services that create them will continue to do so as long as the business model is profitable and the legal risk is negligible.
Attackers use the victim model to generate vast quantities of high-quality training data and to clean and quality-score existing datasets, outsourcing what otherwise would be an expensive and labor-intensive stage of AI development. They query it with pairs of prompts to generate ranked responses – preference data that can be used in reinforcement learning. And perhaps most valuable of all, attackers attempt to extract the victim model’s internal reasoning process – the step-by-step chain of thought it uses to solve problems. For example, Anthropic reported that DeepSeek crafted prompts asking Claude to articulate the reasoning behind a response it gave, effectively reverse-engineering the thought process that makes frontier AI models so capable, despite their developers having already taken steps to summarize these outputs to avoid competitors training on them.
Why it matters
American AI companies have invested significant amounts in compute, data curation, and research talent to build frontier models. Data from EpochAI suggests that OpenAI and Anthropic alone have spent $18 billion on R&D compute since 2024. This potentially creates a competitive asymmetry where American AI companies that must recoup billions in training costs through API and subscriptions are undercut by competitors leveraging distillation attacks. By saving on development effort, Chinese AI companies can train and serve distilled models at little or no cost through their own platforms, or simply open-source them entirely, which would erode American companies’ competitive position. And as AI systems become increasingly central to AI research itself, the stakes of this problem are compounding — distillation doesn’t just transfer today’s capabilities, it can improve the attacker’s starting position for developing tomorrow’s.
Worse, this gives stronger AI capabilities directly to America’s adversaries. A February 2026 CSET analysis of over 9,000 PLA Requests for Proposal from 2023 and 2024 found that the Chinese military is actively seeking to integrate AI into command, control, communications, computers, cyber, intelligence, surveillance, reconnaissance, and targeting — including through DeepSeek models. An October 2025 Jamestown Foundation report similarly found that DeepSeek models are being deployed in Chinese military and public security settings, with PLA procurement documents explicitly calling for tools based on DeepSeek’s models and pilots already underway.
And the pipeline extends beyond China. A February 2026 CSIS analysis found that Russian military developers are actively adapting Chinese open-weight AI models — including Qwen, DeepSeek, and others — for battlefield use in Ukraine, embedding them in air-gapped environments for intelligence processing, reconnaissance analysis, and situational modeling. Sanctions have cut Russia off from developing frontier models independently, making Chinese AI models and smuggled Chinese chips the backbone of Russia’s military AI stack. Distillation that strengthens Chinese models therefore has downstream effects on Russian military capabilities as well.
Given that Anthropic’s Claude, integrated through Palantir’s Maven Smart System, was already reportedly used in combat during the US operation to capture Venezuelan President Nicolás Maduro and subsequently in support of US strikes on Iran, there are concerns if distillation attacks can put somewhat equivalent capabilities in adversary hands.
Additionally, frontier AI models are increasingly used as autonomous coding agents — writing, debugging, and deploying software with minimal human oversight. When these capabilities are distilled, the benefit extends beyond any single application. Better coding agents accelerate AI development itself: generating training data, writing model infrastructure, automating evaluations, and scaling research workflows. Distilling could thus be a compounding dynamic that makes the stakes of this problem grow with each generation of AI systems. This could additionally accelerate China’s entire AI development pipeline.
Distillation may make us overestimate China
To be clear, Chinese AI companies have significant independent training capabilities and do make genuine advances. Their AI capabilities are not due to distillation or other forms of IP theft alone. That being said, distillation still makes Chinese AI capabilities appear more independently developed than they are, since they can to some extent draft off of American innovation in addition to doing their own work.
This risks creating an illusion similar to the Cold War “missile gap,” when American policymakers wrongly believed the Soviet Union had surpassed US intercontinental ballistic missile production, despite the US actually having a substantial lead the entire time. Overestimating Soviet strength via the “missile gap” led to bad defense planning, and we should avoid a similar overestimate of Chinese AI capabilities.

A race to the bottom on safety
A distillation attack can copy a model’s capabilities without its corresponding safeguards, allowing the creation of a capable model with a lower barrier to misuse. If adversarial distillation becomes normalized, it may weaken incentives for individual AI companies to invest in safety measures, since those measures can be stripped away by downstream actors. This can create a race-to-the-bottom dynamic in which the most permissive deployment wins market share and investment in safety is not rewarded.
This is a concern for proliferation of AI misuse given that several AI companies rely on the principle of “marginal risk” when determining whether to release their AI models — assessing how much additional risk their models would create versus the status quo. Chinese models powered by distillation can shift the risk landscape, leading to US developers correspondingly deploying in riskier ways than they otherwise would as justified by not increasing “marginal risk” over a Chinese model. Less safe Chinese models can therefore precipitate the release of American models that are more useful to malicious actors.
What should be done?
The companies conducting these campaigns proceeded because the expected cost was trivial relative to the value extracted. Even under conservative estimates of distillation’s impact, the current enforcement gap — detection without meaningful consequences — invites escalation. Addressing this requires action from both companies and the government, and the appropriate response may need to scale as our understanding of the threat matures. We recommend two measures for the US government:
Entity List the perpetrators. The End-User Review Committee should consider adding the Chinese AI companies conducting distillation attacks to the Entity List. The criteria for addition — “reasonable cause to believe, based on specific and articulable facts” that an entity is involved in activities contrary to US national security or foreign policy interests — appears to be met based on the evidence published by Anthropic, OpenAI, and Google. Entity List designation would require a BIS license, reviewed under a presumption of denial, for any export, re-export, or in-country transfer of items subject to the EAR. Beyond its direct effects, designation signals to the broader AI ecosystem — cloud providers, chip distributors, equipment vendors — that transacting with these entities carries regulatory risk.
Sanction the attackers and their enablers under the Protecting American Intellectual Property Act. The PAIP Act requires the President to identify foreign persons who have knowingly engaged in, or benefited from, significant theft of trade secrets of US persons where that theft poses a significant threat to US national security or economic stability. Sanctions under the PAIP Act are more expansive than Entity List designation. The PAIP Act’s coverage extends to entities that have “provided significant financial, material, or technological support for” the theft — language broad enough to reach the proxy services described above. Outcomes such as inclusion in the Specially Designated Nationals and Blocked Persons (“SDN List”), travel sanctions, and being blocked from financial transactions subject to US jurisdiction, would particularly bite for executives heading up companies conducting and facilitating distillation attacks, especially as Chinese AI companies like Alibaba and Bytedance have significant commercial activity outside China. The first-ever PAIP Act designations were made on February 24, 2026, establishing operational precedent. Whether the aggregate extraction of model capabilities via distillation meets the statutory definition of a “trade secret” would be a novel interpretation, but the national security nexus is well-documented, but the evidence published by Anthropic, OpenAI, and Google could potentially form the basis for designations of the companies conducting distillation attacks.
Additionally, American AI companies are not powerless while waiting for government action. Several steps could significantly raise the cost of distillation attacks:
Implement Know Your Customer (KYC) requirements for API access. Frontier AI companies should require some sort of lightweight identity verification for API customers, particularly for anyone doing high-volume or enterprise-tier access. Just as financial institutions verify customer identities to prevent money laundering, AI companies should verify that their customers are who they claim to be. This would make it substantially harder for proxy services to spin up thousands of fraudulent accounts.
Invest in technical detection and rate limiting. Companies should develop more sophisticated behavioral fingerprinting to identify distillation-pattern queries — such as systematic chain-of-thought extraction, preference-pair generation, and large-scale data cleaning workloads — and throttle or block accounts exhibiting these patterns. Some of this is already happening, but the proxy ecosystem’s persistence suggests current detection capabilities are insufficient.
Better enforce geographic access restrictions. Companies should invest in more robust geolocation and network analysis to identify traffic originating from restricted countries, even when routed through proxies. This includes analyzing patterns like VPN usage, payment methods, and account creation behaviors that correlate with proxy network operations.
Pursue civil litigation against proxy services. Companies should consider legal action against the commercial proxy services that facilitate distillation at scale. Even where direct action against Chinese AI companies is impractical, the proxy services that operate as intermediaries may be within legal reach and their business model depends on low legal risk.
Looking forward
Distillation is a compounding problem. AI systems are increasingly being used to accelerate AI research itself – Anthropic has declared “We build Claude with Claude” and OpenAI has said the same about ChatGPT. As this feedback loop tightens, the US lead in AI becomes not just an economic advantage but a potentially decisive one. A country that maintains frontier AI capabilities can use them to pull further ahead; a country that closes the gap through distillation, chip smuggling, or other means enters that same loop from a stronger starting position than its independent capabilities would allow.
Both American and Chinese AI companies have been explicit that they are trying to build AI systems that would greatly exceed human experts across a wide range of tasks — including tasks related to military capability and national security — and that the path runs through AI systems that substantially automate AI research itself. While there is genuine uncertainty about timelines and feasibility, these are not fringe aspirations; they are stated engineering goals backed by tens of billions of dollars. As AI systems approach the ability to meaningfully accelerate their own improvement, it will matter whether the US or China is ahead — and by how much.
This is the strategic reality that should frame the distillation debate. We are protecting the seed of a capability that, if current trajectories hold, will compound into something without historical precedent. The steps we’ve outlined — Entity List designations, PAIP Act sanctions, KYC requirements, and technical countermeasures — would materially change the cost-benefit calculus that currently makes distillation a rational strategy. The question is whether policymakers will act while the US lead is still large enough to protect.
~
If you liked this article, consider hitting the subscribe button below. You can also follow Theo on Twitter!
 | A guest post by
|
Feels a little weird to write a piece that frames it as a existential threat to the ai industry and admit in a sentence that the true impact of distillation is very unknown? Most of this is written as if distillation can fairly easily transfer capabilities and as you said “steal” models, but I find this to be not supported by the evidence. I’m pretty disappointed in the post.
More info: https://www.interconnects.ai/p/how-much-does-distillation-really
The US AI industry is severely suffering from or being siphoned off by Chinese distillation attackers. How terrible. “By collecting enough outputs (produced by the US AI models), an attacker can train a new model that mimics the original’s capabilities without doing as much underlying research and development work (through investments of billions and billions of US dollars).”
Wow, how wicked the Chinese AI industry is. However, do US AI models all look uncannily like being based upon distillation attacks, which work like robbers robbing original producers all over the world and then presenting the hot goods as their own products?
Seeing robbers being robbed, should we weep or laugh? Or should we call the ensuing robbery crime or karma? Should we call the AI industry world wide legal robbery in the first place, or a joke masquerading as technology innovation?